In this article, we will guide you through some core basic and advanced concepts that are commonly used in Dataddo.
Basic concepts: data source, data destination, and data flow.
Advanced concepts: connectors, authorizers, and data backfilling.
Basic Concepts
There are three basic components which allow you to successfully create a data pipeline: data source, data destination, and data flow.
What Is a Data Source?
A data source is a collection of data from an authorized service that's been connected via a Dataddo connector. Data within the source is automatically refreshed based on the source's configuration.
Data can be extracted from any third-party services as:
- SaaS apps (e.g. Salesforce, NetSuite, HubSpot, Stripe, Klavio, Facebook, Google Analytics 4)
- Databases (e.g. MySQL, Postgres, SQL Server)
- Cloud data warehouses (e.g. BigQuery, Amazon Redshift, Snowflake)
- File storages (e.g. Amazon S3, SFTP).
For more information see our article on data sources.
What Is a Data Destination?
A data destination refers to the endpoint to which data from your sources will be delivered. Destinations include:
- Dashboarding applications (e.g. Databox, Tableau, PowerBI, Looker Studio)
- Databases (e.g. MySQL, Postgres, SQL Server)
- Cloud data warehouses (e.g. BigQuery, Amazon Redshift, Snowflake)
- File storages (e.g. Amazon S3, SFTP)
- Applications (e.g. HubSpot, Salesforce, NetSuite, Zoho CRM)
Dataddo offers an embedded storage called SmartCache, which is designed to provide a simple solution for situations where large data storage volumes or complex data transformations are not required.
However, SmartCache is not intended to replace a data warehouse. As a rule of thumb, if you need to store more than 100,000 rows per data source, or if you require complex data transformations beyond simple joins (e.g data blending, and data union), we recommend using a data warehouse solution.
For more information see our article on data destinations.
What Is a Data Flow?
A data flow in Dataddo represents the connection between a data source (or multiple sources) and a destination. For example, transferring data from Facebook Ads (source) to Looker Studio (destination).
Key considerations:
- One Dataset, One Flow: For fixed-schema connectors like HubSpot Analytics, each dataset must have its own flow. This means that if you need to extract multiple datasets, such as contacts and deals, you’ll need a separate flow for each.
- Multi-Account Extraction: If multiple accounts share the same schema (i.e., identical attributes and metrics), their data can be combined into a single flow using data union. For example, data from multiple Google Analytics accounts can be consolidated and extracted together.
Dataddo’s unique architecture decouples data extraction from data delivery, allowing flexible and scalable configurations. This means a single Salesforce data extraction can be routed to multiple destinations, such as different data warehouses or BI tools, enabling efficient use of resources.
For more information see our article on data flows or refer to the following articles for a more comprehensive overview of use cases that are possible in Dataddo:
- Simple Data Integration to Dashboards
- Batch Ingestion to Data Warehouses
- Batch Ingestion to Data Lakes
- Database Replication
Advanced Concepts
In this section, you will find the terms connectors, authorizers, and data backfilling. Although all of these are still very commonly used in Dataddo, you most likely are able to use them without even actively knowing about it.
Connectors
The use of connectors is implicit as you encounter it as soon as you start using Dataddo without even actively noticing.
Connectors allow Dataddo to extract data from your services. When you configure a connector, you define what data you want to extract and as such you create a data source in Dataddo.
There are three types of connectors available: universal connectors, fixed-schema connectors, and custom-schema connectors. For more information, see our article on types of connectors.
Authorizers
Similarly to connectors, you may encounter the use of authorizers without even actively noticing.
Authorizers represent any authentication and authorization data that are used to connect to a source or destination. You can re-use a single authorizer for multiple sources or destinations. See our article on authorizers for more information.
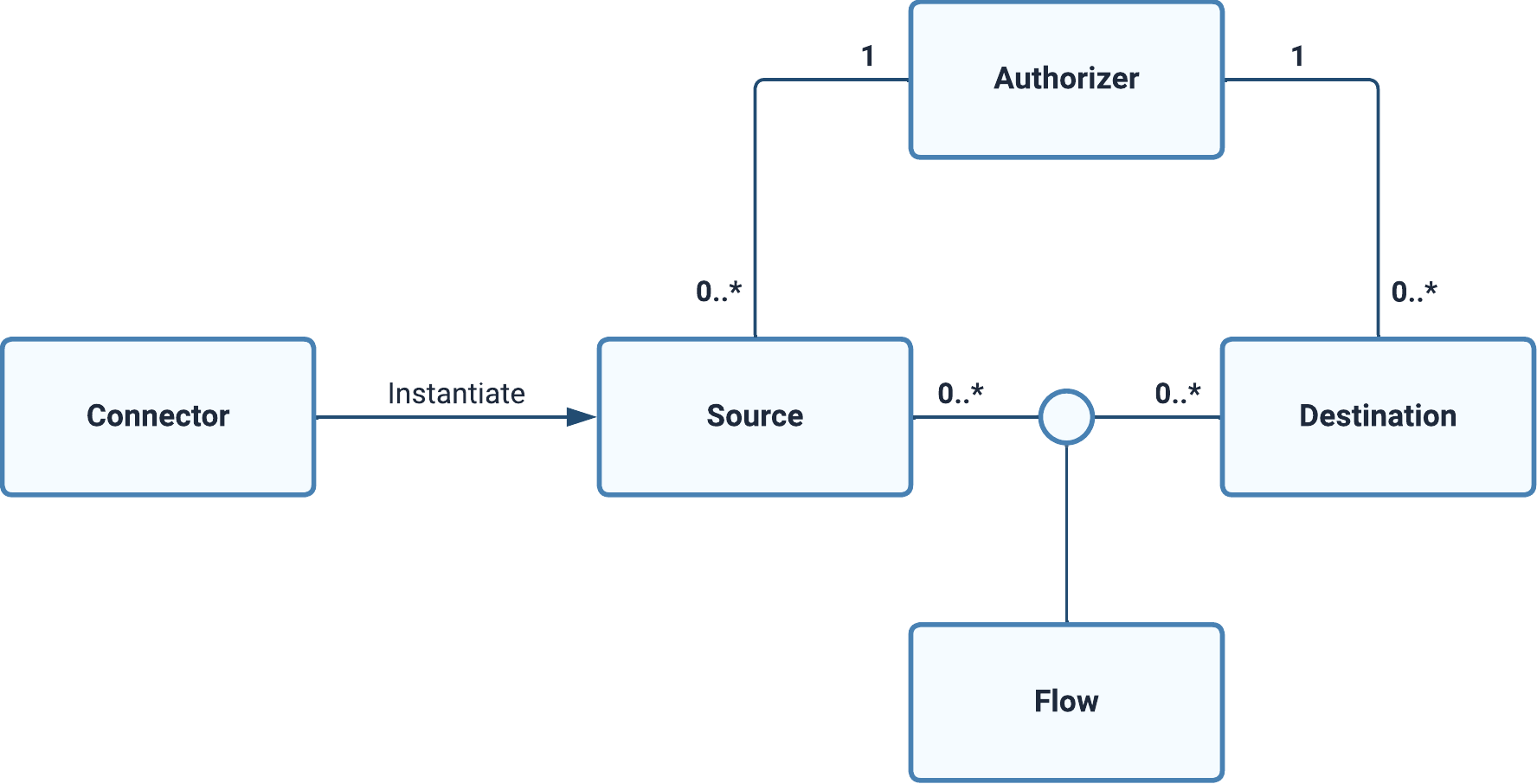
Relationship Between Core Dataddo Components
Now that we know what core Dataddo components are, we can take a look at how they are used.
- Firstly, a connector instantiates a data source.
- Simultaneously, an authorizer bears the credentials for access to synchronize data in a data source or write data to a data destination.
- Finally, a data flow connects everything as it gives you the flexibility to create M:N assocations between data sources and data destinations.
Data Backfilling
Data backfilling is used to load historical data from your sources to your destinations. This is particularly important for aligning your data pipeline with broader data management strategies.
For more detailed explanation and a how-to guide, check the following articles: