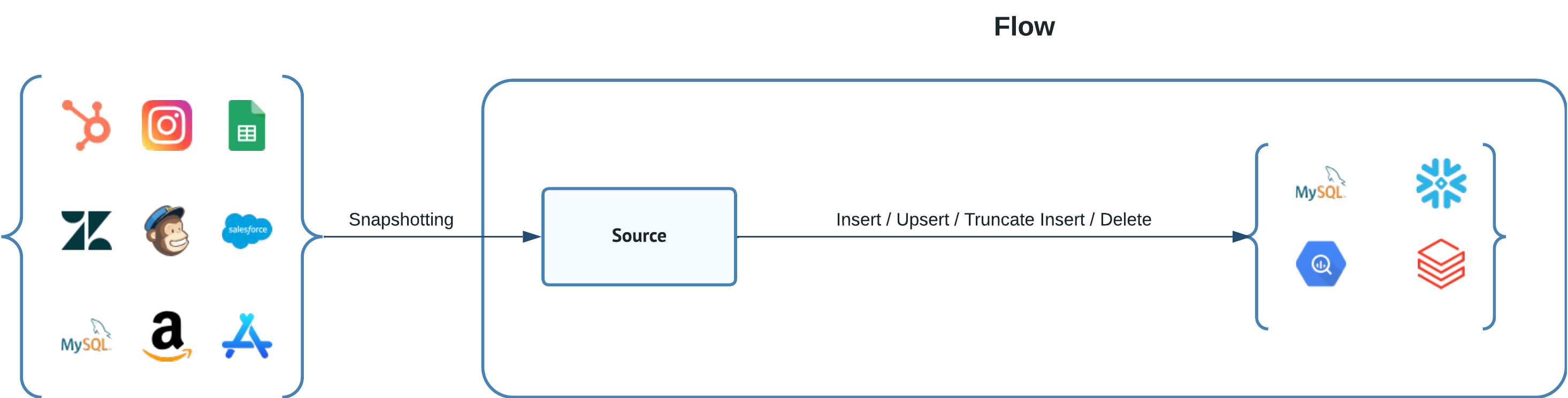
Dataddo seamlessly facilitates data delivery to an extensive range of data storage solutions. This includes traditional databases like SQL Server, MariaDB, and PostgreSQL, as well as contemporary Cloud-based Data Warehouses such as Snowflake, Redshift, Google BigQuery, Databricks or Azure Synapse.
Beyond its extensive compatibility with various data storage technologies, Dataddo offers multiple write modes — including insert, upsert, truncate insert, and delete. This versatility ensures that the platform can seamlessly integrate with and accommodate a diverse range of data management architectures.
Understanding your Data
Before diving into the specifics of data configuration, it's vital to have a solid understanding of your data. This means recognizing its unique properties, how it changes over time, and how these changes should be reflected in your analysis.
Please refer to the decision schema below, which is designed to help you better understand your data.
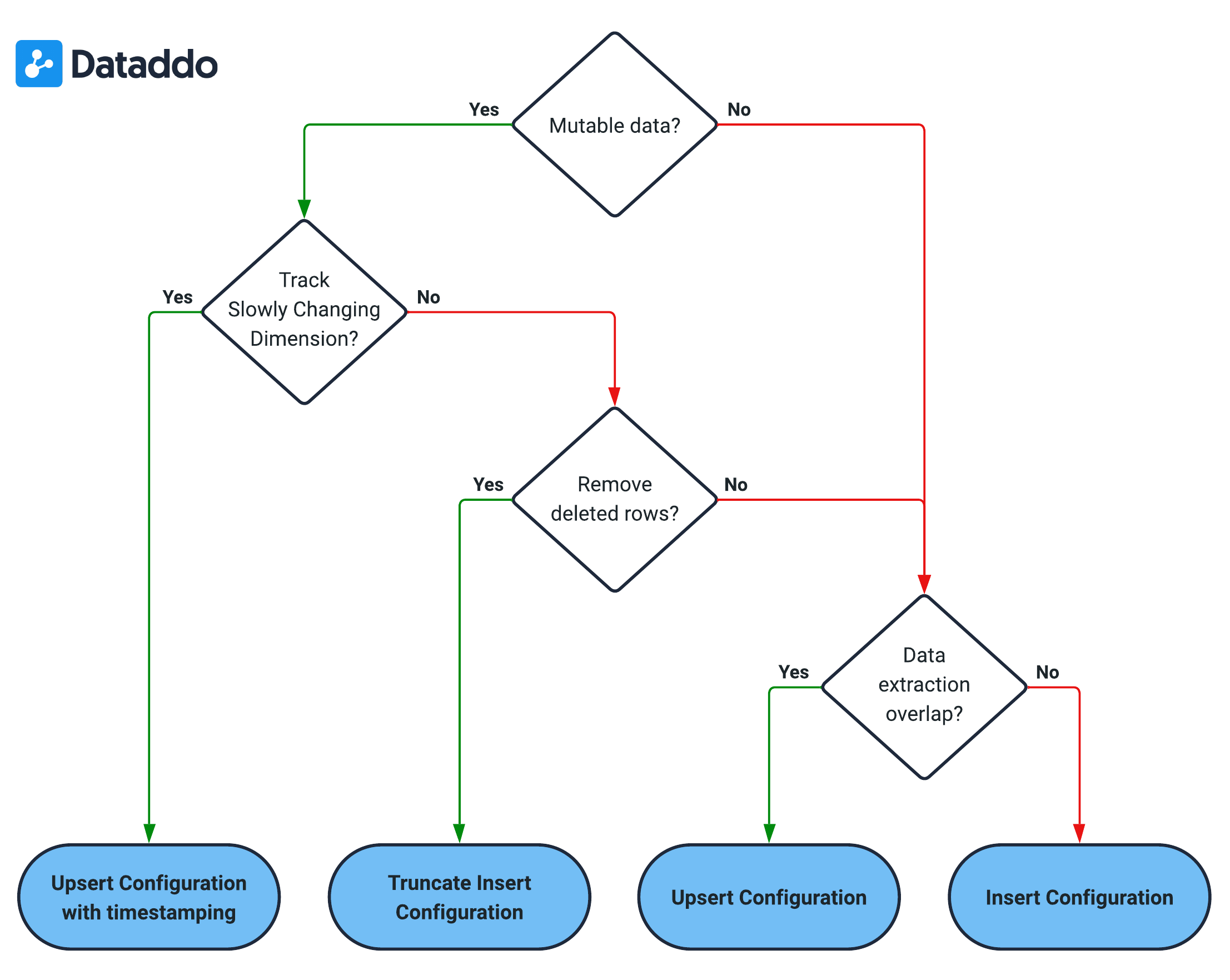
Is data mutable?
This question refers to whether the data, once extracted and defined by a common identifier, can change in subsequent extractions. In other words, it is asking if the data is subject to alteration after its initial extraction.
As an example, consider a row containing an invoice with a unique identifier, like an invoice number. If the status of the invoice changes from 'Pending' to 'Paid', would this update be captured in your next data extraction? If yes, then the data is mutable - it changes over time.
Need to Track Slowly Changing Dimensions (Changes Over Time)?
This question assesses if it's necessary to monitor and record the evolution of data values over time. In data warehousing, this concept is known as Slowly Changing Dimensions (SCD). It involves tracking changes (like updates or modifications) to data elements, keeping a historical record, and observing how these changes impact the system over time.
As an example, think about a product's price in a Product table. If the price changes, do you need to keep a record of the old price, or is it enough to just update to the new price? If keeping the historical price data is important for your analysis or business decisions, then you need to track Slowly Changing Dimensions.
Does deleted rows need removing?
This question determines if the data extraction process must account for rows that have been deleted in the source data. In other words, it's asking if the removal of records in the source must be reflected in the destination.
As an example, suppose a record is deleted from the source data. Must your data set or dashboard also reflect this deletion? If 'yes', then the deleted rows need removing.
Does Data Extraction Overlap Periods?
These questions get at the idea of whether your extraction process can include data from the same time period in multiple extractions.
As an example, consider your daily extraction process. Does each extraction include data from previous days? For instance, does Tuesday's extraction include data from Monday, and does Wednesday's extraction include data from Tuesday? If 'yes', your data extraction has overlapping periods. If each extraction only contains new data from that day, then there is no overlap.
Configurations
Upsert with Timestamping
When you have mutable data and need to track slowly changing dimensions in your data warehouse.
- Configure Source with Dataddo Extraction Timestamp. This attribute setting during the data source configuration process marks the time of each extraction, enabling tracking of changes over time.
- Set Write Mode to Upsert. During the Flow configuration, select the write mode as Upsert.
- Configure the Upsert Composite Key. Ensure that the Upsert Composite Key includes the "Dataddo Extraction Timestamp" (as set in step 1). This will help track when each change occurred while ensuring that existing rows with the same identifiers are updated and new rows are added.
Imagine you have invoice data where each invoice has a unique invoice number. An invoice's status might change from "Pending" to "Paid". With the "Upsert with Timestamping" configuration, if you extract the data again, the invoice's status in the data warehouse will be updated to "Paid", and the "Dataddo Extraction Timestamp" will indicate when this change was detected.
Upsert
When your data is mutable but you don't need to track changes over time.
- Set Write Mode to Upsert. During the Flow configuration, opt for Upsert write mode. This ensures that existing rows with the same identifiers are updated, and new rows are added, without timestamping the changes.
- Configure the Upsert Composite Key. Determine and set the unique identifier(s) that should be used as the Upsert Composite Key. This key ensures that existing rows with the same identifier(s) are updated, and new rows are added.
Imagine you have a dataset of products with unique product codes. The product description might change, but the product code remains constant. Using the "Upsert" configuration, if the product description changes and you extract the data again, only the product description will be updated in the data warehouse based on the unique product code which is set as Upsert Composite Key.
Truncate Insert
When data is mutable, and you want to replace the old dataset with the newly extracted dataset in its entirety.
- Set Write Mode to Truncate Insert. In the flow settings, select Truncate Insert. This will erase the existing dataset in the warehouse and replace it with the new dataset from the current extraction.
Imagine you run an e-commerce platform where you only focus on analyzing the current month's sales data. At the beginning of July, you extract data and analyze sales trends. When August starts, you no longer need July's data. Using "Truncate Insert", you can replace July's data with August's sales records, ensuring your warehouse only contains the most relevant month's information.
Insert
When data is not mutable and doesn't overlap with extractions, such as unique daily logs.
- Set Write Mode to Insert. Opt for Insert in the flow configuration. This ensures that every new set of extracted data is added to the data warehouse without modifying or removing any existing data.
Consider a logging system that creates a new entry for every action in a software. Each log entry is unique and doesn't change. Using the "Insert" mode, each new extraction will add log entries to the warehouse without altering any of the previous entries.
Data Transformation Capabilities
Transformations can be employed at different stages in the data processing journey to ensure your data is tailored to your specific needs.
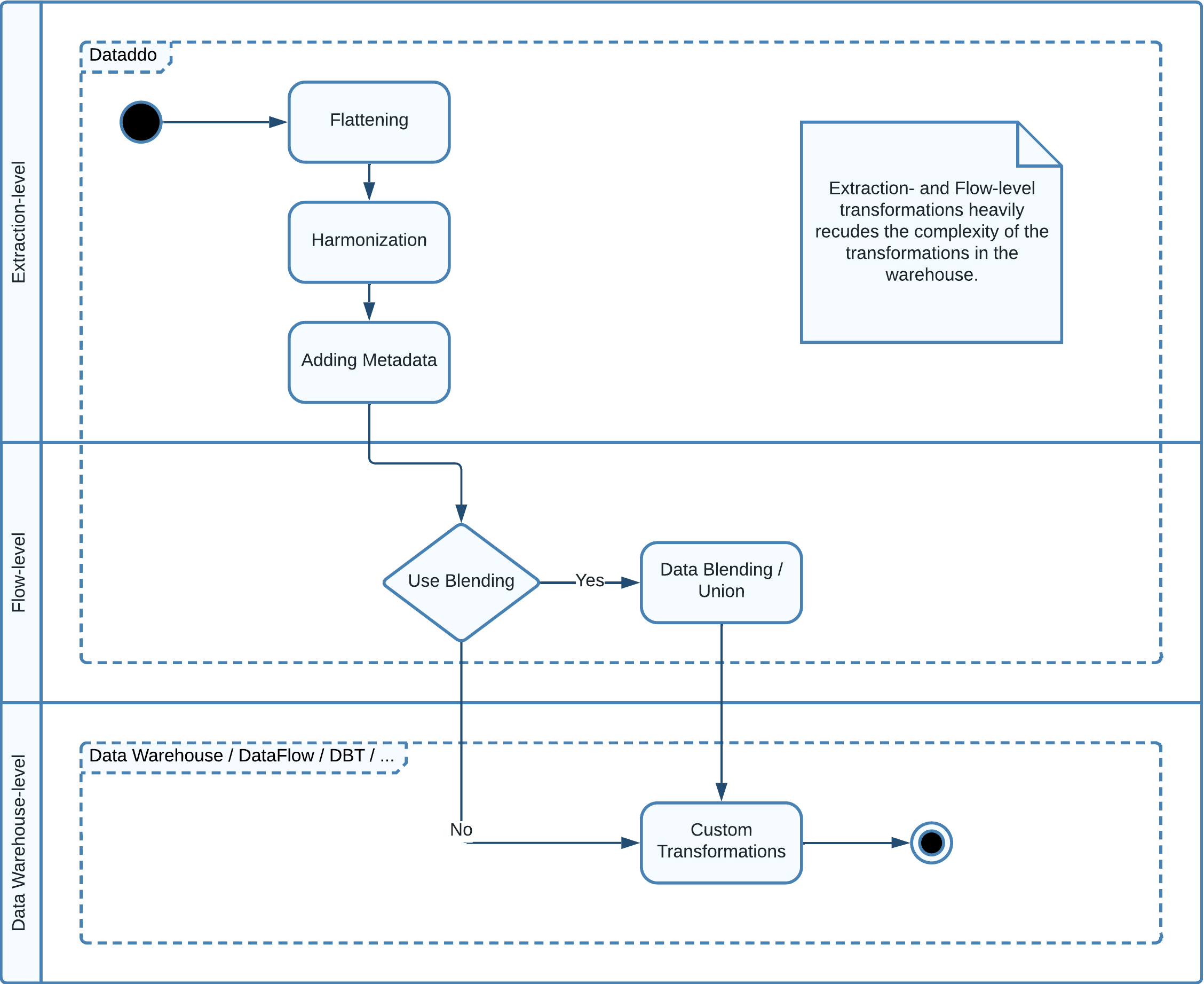
- Extraction-Level Transformations. These are automatically performed by Dataddo, ensuring data is warehouse-ready. Key tasks include data flattening, harmonization, and the inclusion of relevant metadata, such as the Dataddo extraction timestamp for Slowly Changing Dimensions (SCD). By managing these preparatory steps, Dataddo significantly reduces the complexity of subsequent transformations within the warehouse. This proactive approach means the data is harmonized to a level where it's primed for subsequent analysis or further processing within the warehouse environment. For unique configuration demands, our generic connectors, like the JSON Universal Connector, are available for tailored adjustments.
- Flow-Level Transformations. Engaged when data from different sources need to be consolidated before being ingested into the data warehouse. Dataddo's Data Union and Data Blending functionalities facilitate this layer of transformation, ensuring that data from diverse sources can seamlessly integrate into a unified storage schema.
- Warehouse-Level Transformations. At this stage, transformations are executed either within the warehouse itself or by utilizing third-party tools that operate in conjunction with the data warehouse, such as AirFlow or DBT. These tools and intrinsic capabilities of the warehouse allow users to reshape, clean, or enhance the data to perfectly fit their specific analytics or business intelligence requirements. Whether it's creating materialized views, restructuring tables, or performing advanced calculations, these transformations ensure the data is optimally organized for in-depth analysis.