Batch Extraction
- 4 Minutes to read
- DarkLight
Batch Extraction
- 4 Minutes to read
- DarkLight
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Batch extraction is a common method used by many connectors (for more information, see our article on connector types), to retrieve data at set intervals. It requires establishing a specific extraction frequency and is beneficial when managing substantial data volumes or when real-time updates aren’t necessary. This strategy balances data freshness and system resource optimization.
Extraction Frequency
Extraction frequency (or snapshotting frequency) refers to the regular intervals at which Dataddo retrieves data from your connected services. Though initially set during data source configuration—with Dataddo offering a recommended frequency for optimal data retrieval based on the source’s characteristics—you can later modify it to suit evolving requirements and preferences.
Adjusting Extraction Frequency
You can adjust the extraction frequency after the creation of a data source by following these steps:
- On the Sources page, click on your data source.
- Navigate to the Snapshotting tab.
- Choose a predefined frequency (e.g. hourly, daily), or choose a custom expression for finer control (for more details, see how you can set dynamic date range).
- Save to confirm the changes.
Maximum Extraction Frequency
Dataddo can support extraction intervals as minimal as 1 minute. However, for some services, e.g. Google Analytics 4 or Facebook Ads, such a frequent interval may not be possible due to their data freshness limitations. To ensure both accurate data and compliance with service limitations, Dataddo will suggest an optimal extraction frequency during the data source configuration process.
Snapshot Keeping Policy
A snapshot captures the state of data from a source at a specific point in time. Each data extraction creates a new snapshot and all snapshots collectively form a time series.
Snapshot keeping policy determines the action taken upon creating a new snapshot. Dataddo offers two options:
- Replace: The new snapshot overwrites the existing data, maintaining only the most recent snapshot.
- Append: All snapshots are preserved, with the new snapshot simply added to the existing collection.
Select a Snapshot Keeping Policy
Adjust your snapshot keeping policy with the following steps:
- On the Sources page, click on your data source.
- Navigate to the Snapshotting tab.
- Under the Snapshot Keeping Policy section, select either Replace or Append for your data.
- Save to confirm the changes.
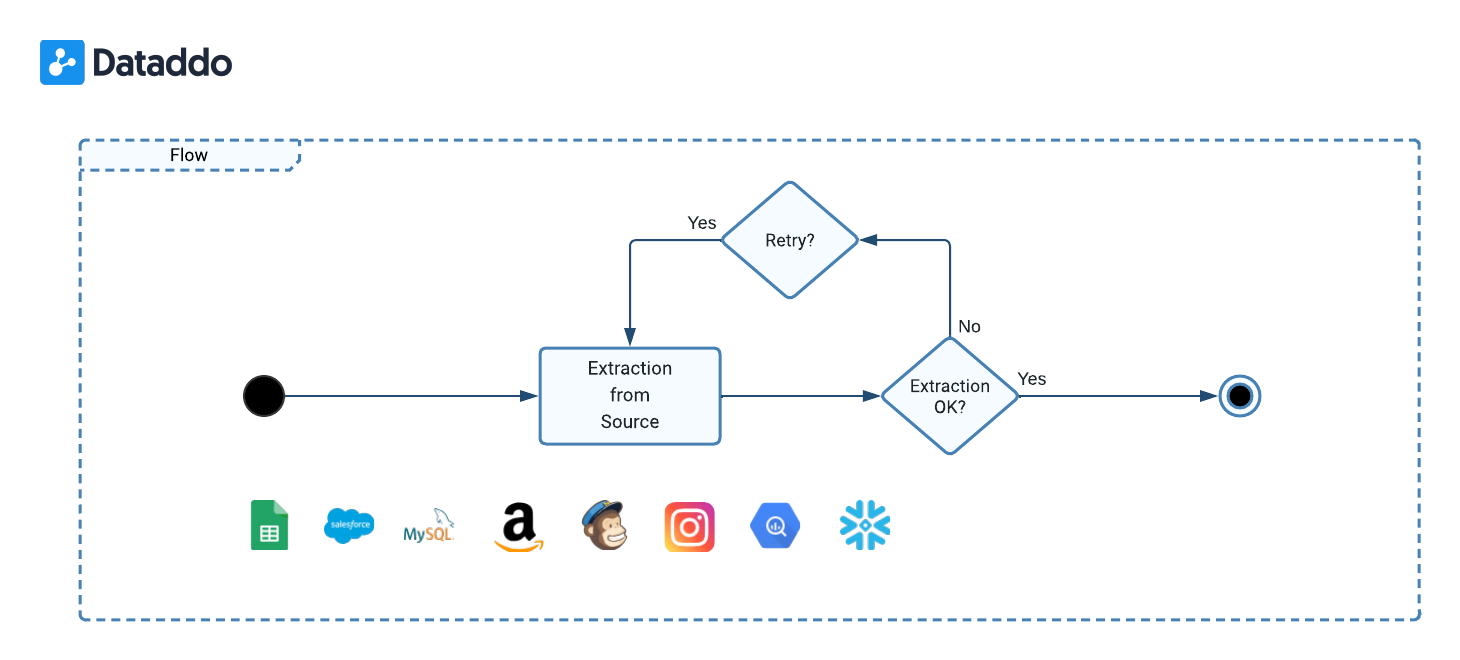
Ensuring Reliable Data Extraction
To ensure that all extraction processes are both reliable and robust, there are the following error handling mechanisms in place.
- Automatic Retries: In the event of an error during extraction, the system automatically retriggers the extraction up to three timess, ensuring transient issues do not hinder data extraction.
- Error Clasification: Various scenarios can elicit errors during extraction, such as:
- The extraction yields 0 rows, signaling no new data. If this outcome is expected, please enable the Allow Empty option.
- Authorization to your service is unsuccessful, usually indicating permissions or authentication issues. To fix this, please reauthorize your service.
- The schema of the retrieved data diverges from the data source's defined schema. Please modify the schema.
- Anomalies or issues that stem from the source system.
- Permanent Broken State: If extraction remains unsuccessful after three retries, Dataddo will classify the data source as broken. Please refer to our article on fixing a broken data source.
Batch Size Limitations
Batch extraction, used with API-based connectors like Salesforce, Hubspot, Google Analytics 4, and Netsuite, often meets challenges due to third-party API limits. These can include restrictions on the timeframes, the number of API calls, and the amount of data per call.
To address these issues, Dataddo employs the following strategies
- Making multiple API calls at once
- Automated pagination
- Dynamic adjustment of request sizes.
This approach aims to efficiently retrieve data while staying within the API's allowed limits.
Multi-Account Extraction (MAE)
Multi-Account Extraction (MAE) is a feature that enables the simultaneous data extraction from multiple accounts or properties, such as several Facebook or Google Analytics accounts, in a single source setup. This functionality is built for administrators managing multiple accounts, ensuring uniformity in data extraction settings across all accounts.
Enabling MAE
To use the MAE feature, please contact our Solutions team for assistance with the setup. Note that you will need administrator access to all the accounts you want to integrate with MAE. The data source configuration you choose during the setup will be consistent across all accounts. To tell the data apart for each account, make sure you pick unique identifiers such as account name/ID or page name/ID.
You can choose all of your accounts or only a selected few. In your request to enable MAE, please let us know which accounts you wish to extract data from.
Connectors Supporting MAE
- Facebook connectors: Facebook Ads, Facebook Graph, Facebook Leads, Facebook Page, Facebook Post, Facebook Video
- Google connectors: Google Analytics, Google Analytics 4, Google Ads
- Instagram connectors: Instagram Ads, Instagram Media, Instagram Story, Instagram User/Business
- LinkedIn Ads
- Snapchat
- TikTok
- Xero
Number of Accounts for MAE
MAE is included in the paid plans and you will not be charged extra for it.
| Plan | Number of Accounts |
|---|---|
| Free | N/A |
| Data to Dashboards | Up to 10 accounts |
| Data Anywhere | Up to 30 accounts |
| Headless | Unlimited |
However, depending on the amount of data your accounts have, more than one MAE might be necessary.
Related Articles
Was this article helpful?