Dataddo's Full Data Re-Sync feature loads all historical data from a connected source to storage solutions like BigQuery, Snowflake, or Databricks. This makes your data storage comprehensive, including both current and past data, improving your analytics and reporting capabilities.
Some common use cases for full data re-sync are:
- Recovering lost data
- Backfilling historical data
- Fixing past sync issues
See the Full Data Re-Sync video tutorial.
Prerequisites
Before using the Full Data Re-Sync feature, ensure the following conditions are met:
- Compatible Data Destinations: To maintain data consistency, the feature is only available for destinations that support upsert mode (e.g., databases, data warehouses like BigQuery, Snowflake, or Databricks).
The Process
To start the full data re-sync, on the Flows page, trigger the extraction and select your date range. Dataddo then manages the sync process while handling any limitations set by the data source. For example, large requests are automatically split into smaller jobs to comply with API restrictions.
Users can oversee re-sync jobs through a dedicated dashboard, ensuring transparency and control.
Full Data Re-Sync runs separately from regular syncs to prevent disruptions to ongoing data pipelines.
Large datasets may take longer to process.
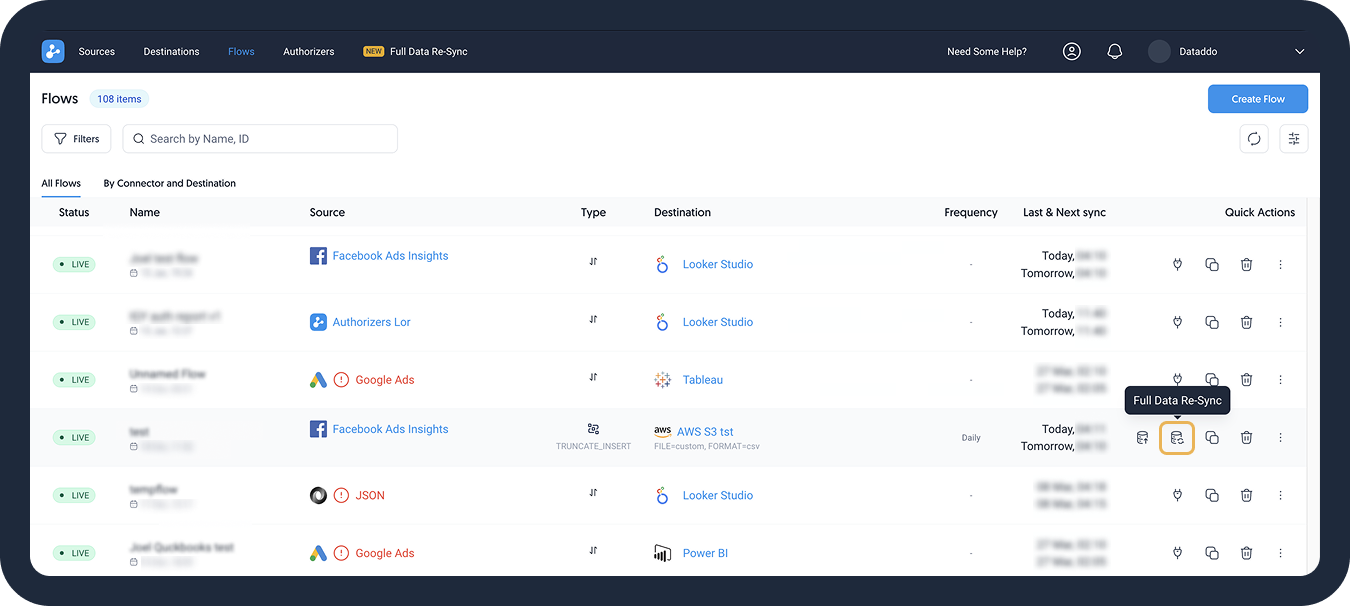
Trigger the Extraction
- Navigate to the Flows page.
- Next to your flow, click on the Full Data Re-Sync icon.
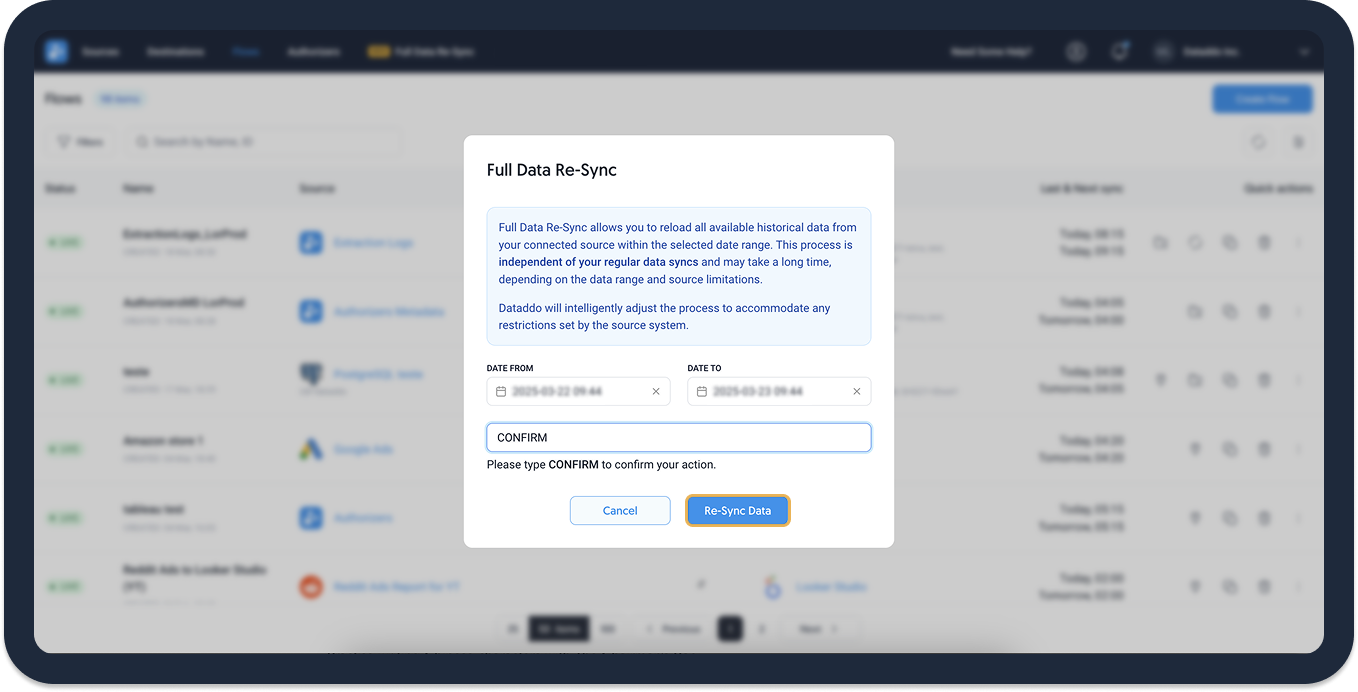
- Select your date range and Confirm.
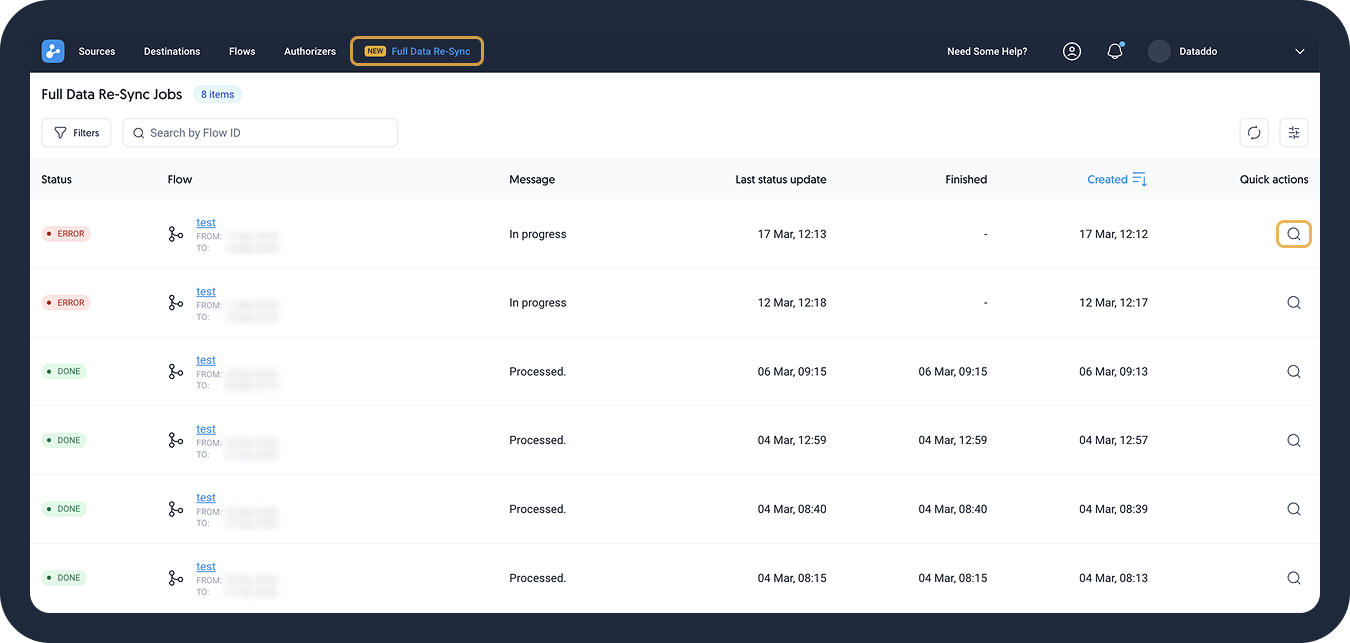
Full Data Re-Sync Jobs Overview
After you trigger the process, check the process on the Full Data Re-Sync Jobs overview page. Here, you'll find the following information information:
- Job status
- Link to the original flow (click on the flow name for redirection)
- Last re-sync update, finish date, creation date
- Re-sync log under Quick Actions