A transformation pipeline serves as a structured framework for data transformation, modeled after the concept of data processing pipelines.
This structure allows API responses from third-party services to undergo multiple transformation stages, rendering the data compatible for ingestion by Dataddo. When using universal connectors, data can be fetched from diverse sources and transformed accordingly.
Guides
How to Write a Transformation Pipeline Script: A step-by-step guide on how to write a transformation script.
Transformation Pipeline Practical Examples: A number of transformation script examples that you can try out in the Dataddo.
References
Transformation Pipeline Stages: A comprehensive list of transformation pipeline stages and the descriptions of their functions.
Transformation Pipeline Expression: A comprehensive list of transformation pipeline expressions and the descriptions of their functions.
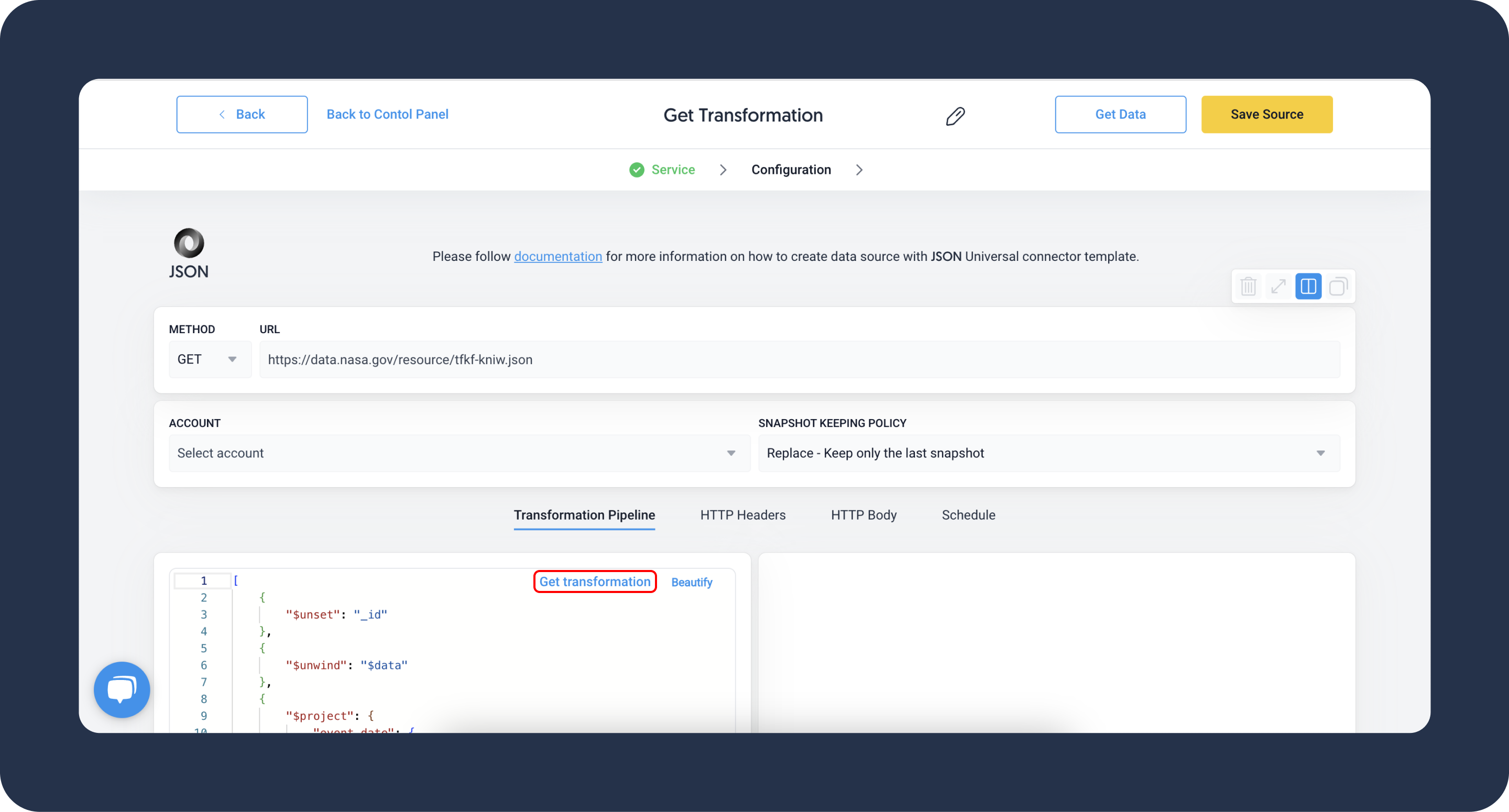
If you are not sure where to start, when creating your data source, you can click on the Get transformation button. In most cases, it will auto-generate a transformation script for you.
Transformation Pipeline Stages
The Dataddo transformation pipeline consists of multiple stages. Each stage refines the API response as it progresses through the pipeline. Some stages can be used multiple times within a single pipeline.
For a detailed overview of each stage, refer to the list of transformation pipeline stages.
Types of Transformation Pipeline Expressions
Pipeline expressions, employed within certain stages, define specific transformations to the input data. Expressions perform a computation or an operation on the input, and then return a value. They allow for in-memory transformations but can't access data from other objects within the pipeline.
Expressions can be simple, directly referencing a value, or complex, performing operations on data. Here's a breakdown of the different types of expressions:
Field Paths
Field paths expressions directly reference fields within the documents that are being processed by the aggregation pipeline. They are indicated by the $ symbol followed by the field name (e.g. $user.name).
Aggregation Variables
Aggregation variables are predefined variables which can be used in expressions. These include $$NOW (the current datetime), $$ROOT (the root document), and others. These variables provide useful shortcuts and context-aware data that can be incorporated into aggregation operations.
For an in-depth explanation of these expressions and their functions, refer to the list of operator expression.
Literals
Literals are constant values that can be used in expressions. Literals include values like strings, numbers, booleans, etc. The $literal operator is used when you need to include a value that starts with a $ or a numeric/boolean value in an expression object, ensuring that it is treated as a constant rather than a field path or projection flag.
Expression Objects
Expression objects define expressions using field-value pairs. The values can be any valid expression, including literals, field path expressions, and operator expressions. If the value is a numeric or boolean literal, MongoDB treats it as a projection flag in the $project stage, unless it is wrapped in a $literal expression.
{ <field1>: <expression1>, ... }
Operator Expressions
Operator expressions are similar to functions in other programming languages. They are invoked with the $ symbol followed by the operator name and take an array of arguments. They perform various operations, such as mathematical calculations, string manipulation, logical operations, etc., and return a result. For example, { $add: [ "$field1", "$field2" ] } would add the values of field1 and field2 together.
{ <operator>: [ <argument1>, <argument2> ... ] }
For an in-depth explanation of these expressions and their functions, refer to the list of operator expression.