The May release introduces key infrastructure upgrades focused on pipeline performance, data flexibility, and better platform visibility.
The headline update is the rollout of Zero-Copy Connectors across our entire library, allowing you to stream data directly into downstream tools using Apache Arrow to eliminate intermediate storage costs and pipeline latency. We have also upgraded our core platform with an advanced API backbone to support Apache Airflow orchestration and AI-driven configurations.
Additionally, this release adds Authorizer ID visibility to the Destination overview page for faster troubleshooting, introduces new connectors (including DoubleVerify and Leadfeeder), and includes critical stability fixes for pipeline alerting and large data volume processing.
Connectors
New Connectors:
- Apache Iceberg (destination)
- HubSpot Associations (destination)
- Leadfeeder
- Umatch
New Datasets, Attributes, and Metrics:
- Instagram Organic: Daily Insights Transposed dataset added.
Connector Updates:
- Facebook Graph: Daily granularity now supported for the Business Follows Unfollows dataset.
- Gingr: Historical data can now be extracted.
- Gusto: The connector has been updated to the newest version.
- Mercado Libre: Product Ads Items - Daily Breakdown dataset was updated to exclude deprecated endpoints.
New Features
Next-Gen "Zero-Copy" Data Pipelines
To match the speed of modern cloud environments and AI, we are launching Zero-Copy Connectors across 100% of our connector library.
Traditionally, pipelines require extracting, copying, and staging data through multiple warehouse layers before it becomes usable. While traditional data warehouses still have their place, Dataddo provides the flexibility to skip these intermediate steps and serve data directly to your downstream tools in Apache Arrow format.
Why this matters:
- Eliminate the "Compute Tax": Bypasses heavy serialization and deserialization costs by streaming data directly into memory via Apache Arrow.
- Reduce Storage & Compute Overhead: Eliminates unnecessary physical data copies to minimize infrastructure inefficiencies and data warehouse costs.
- Remove Pipeline Latency: Sends data instantly to downstream tools like Jupyter notebooks, dashboarding apps, or Claude.
- Optimize for AI Infrastructure: Feeds text and data streams directly into AI models without waiting for rigid, traditional transformation steps.
- Simplify Data Governance: Removes the need for landing zones, pipeline delays, and duplicate files unless you explicitly want them.
UX/UI Enhancements
Further Grids Improvement
Thanks to customer feedback on how users interact with the platform, our latest round of grid improvements is rolling out gradually to make the experience with the platform more fluid.
The new user-centric design is now faster, more intuitive, and visually polished.
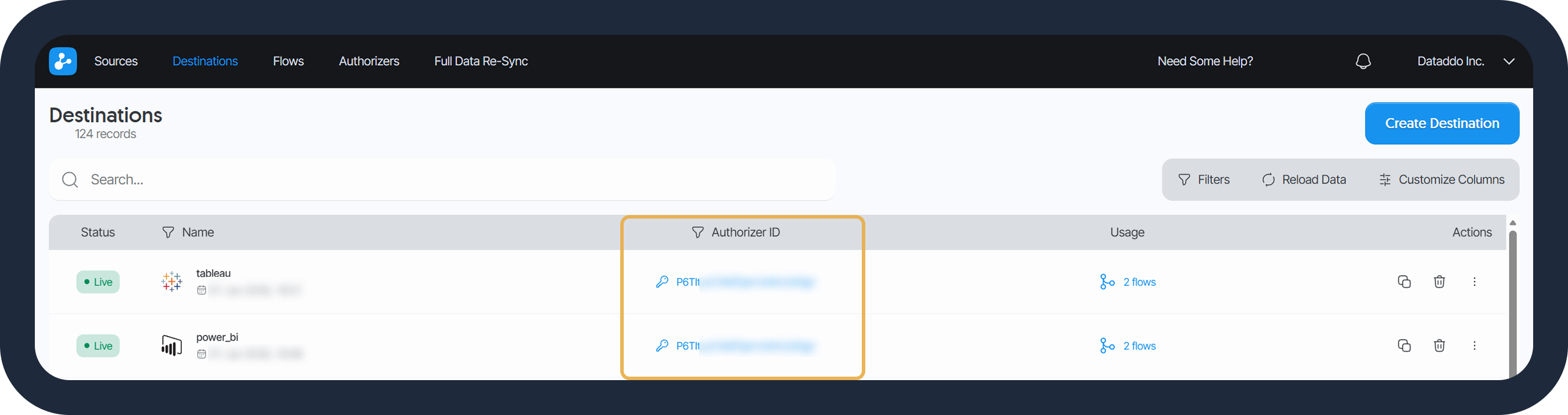
Destination Overview: Authorizer ID Visibility
To improve at-a-glance visibility across the platform, the Authorizer ID used during setup is now displayed directly on the destination overview page. This allows:
- Instant Context: Quickly identify exactly which account or credential powers each destination without needing to click into individual settings.
- Faster Troubleshooting: Streamline access audits and resolve connection updates efficiently by having all relevant data points in a single, scannable view.
Platform Updates
Advanced API Backbone & Smart Orchestration
We have reinforced the core of our platform's API layer to provide a highly stable, enterprise-ready foundation for your data workflows. This enhanced API framework now unlocks two major capabilities:
- Apache Airflow: Seamlessly leverage Apache Airflow for robust, enterprise-grade orchestration across complex data projects.
- AI-Driven Configurations: You can now deploy AI-based configurations directly on top of our API, making workflow setup and customization faster and more intuitive.
Bug Fixes
Connector Fixes
App Store Connect:
- Fixed an issue causing data extraction to fail with the
resource not founderror message.
Atlassian JIRA:
- Fixed an issue with the Issues dataset returning empty values for the
descriptionfield. - Fixed pagination issues with the Board Sprints dataset.
Databox:
- Fixed an issue preventing Databox to be selected during flow creation.
Databricks:
- Fixed an issue preventing a successful source creation and data extraction.
Facebook Ads:
- Fixed an issue with missing creatives in the Ad creatives dataset.
- Fix an issue occurring during the duplication of sources that use the Action Type dataset.
Google Ads:
- Fixed an issue preventing metrics from being selected for an account with manager-level permissions.
Google Display & Video 360:
- Fixed missing
Partnerfield that is required for YouTube queries. Previously, this field was optional. The new default has been set to “single partner”.
LinkedIn Ads:
- Fixed an issue disabling the selection of metrics and attributes when creating a source using the LinkedIn Ads by Campaign Analytics dataset.
Mercado Libre:
- Fixed an issue causing duplicates when extracting data at the creative level.
NetSuite SuiteAnalytics V2:
- Fixed an issue preventing source creation or causing no data to be extracted.
Power BI:
- Fixed an issue causing the destination creation to fail with the
Destination ID is not seterror message.
Salesforce Pardot:
- Fixed an issue causing empty or null values to be extracted when using the List Email Statistics V5 dataset.
Xero:
- Fixed an issue with source extraction by adjusting API rate limits.
General Fixes
Data Union:
- Fixed an issue causing unioned sources with liberal policy to fail data ingestion at scheduled time.
Extraction of Large Data Volumes:
- Fixed a bug causing data extraction to fail with the
object to insert too large. size in bytes: 29764081, max size: 16777216error message.
Logs Scroll Function:
- Fixed a bug causing the scroll function on the activity logs window to malfunction.
Overview Pages:
- Fixed a UI bug preventing users from closing the debug source detailed view.
- Fixed a bug causing the filter facets on the source and destination overview pages to malfunction.
Pipeline Status Alerts:
- Fixed a bug that caused transient decoding errors to trigger false "broken" pipeline alerts, despite successful data delivery upon automated retry.
Reverse ETL Destination Selection:
- Fixed a bug preventing the selection of applications as the destination.
Source Configuration:
- Fixed an issue preventing source status change.
- Fixed a bug during source edit causing the
appendsnapshotting policy to be changed toreplace.