Dataddo enables data delivery to various data storage technologies. We support not only traditional databases such as SQL Server, MariaDB, and PostgreSQL, but also modern data warehouses and data lakes like Amazon Redshift, Google BigQuery, and Azure Synapse. Moreover, our platform also covers file storage solutions like Amazon S3 and protocol-based data transfers such as SFTP, ensuring comprehensive coverage of all your data management needs.
Find the complete list of supported storage platforms on the Dataddo Connectors page.
Architecture Considerations
The process of delivering data to data storages is initiated after data extraction from the data source is completed. However, by setting a custom write trigger, it's possible to de-couple the writing process from extraction, offering more granular control over data handling.
When data is written to your storage, it always includes the full content from the most recent extraction. This method ensures that your dataset remains comprehensive and up-to-date for analyses and reports.
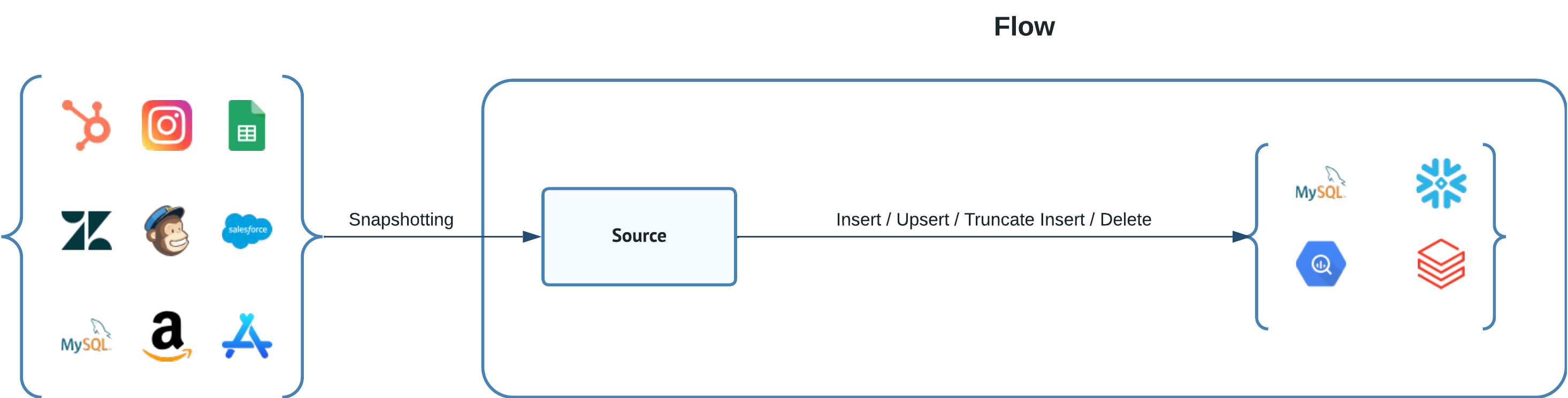
You can select from various data writing modes to ensure consistency in your data storage.This adaptability allows users to fine-tune the data delivery method to match specific data management and analysis needs, ensuring the precision and relevance of stored data.
Automatic Table Setup
Automatic table setup simplifies configuring your data storage by establishing an optimized table structure (or schema) during the initial setup. This includes defining column names, data types, and indices. However, once the table schema is created, it will not be updated automatically. This ensures the consistency of your data as unintended changes are avoided. Any later modifications to the table structure need to be made manually, allowing for accurate control over your data environment.
When setting up data storage, especially with specific write modes like upsert, this feature is essential. For new tables, it not only creates an efficient table structure but also adds the necessary indexing during the first data load. It's important to note that if the upsert write mode is chosen for an existing table, automatic indexing can't be added retroactively.
Adaptive Data Ingestion
Dataddo adjusts to your data volume and selects the most suitable data loading method for your specific data warehouse or database. Adaptive data ingestions works in the following way:
- For smaller data volumes, Dataddo uses batch insert queries for efficiency.
- As the volume grows, it switches to loading through files in object storage.
- When data volume is very large, Dataddo uses streaming for effective data management.
Different data warehouses or databases might need specific data loading techniques. Adaptive data ingestion can accommodate these requirements. However, using some of these techniques might require extra setup or higher permission levels. For example, to optimize SQL Server's data loading using object storage, users might need additional configuration.
Write Modes
Dataddo offers several write modes to control how data moves into your chosen destination. These modes are
Each mode has a specific purpose and provide flexibility to accommodate various data handling strategies, making it easier to add new records, update existing ones, or manage potential duplicates. Understanding these write modes ensures efficient data transfer and data integrity.
Insert
Insert is the default write mode. Insert appends new data to existing records in the destination. This mode is suitable for scenarios where data continuously accumulates. However, if there is overlapping data (e.g. some of the information has been previously stored), there's a risk of duplicate entries in your dataset.
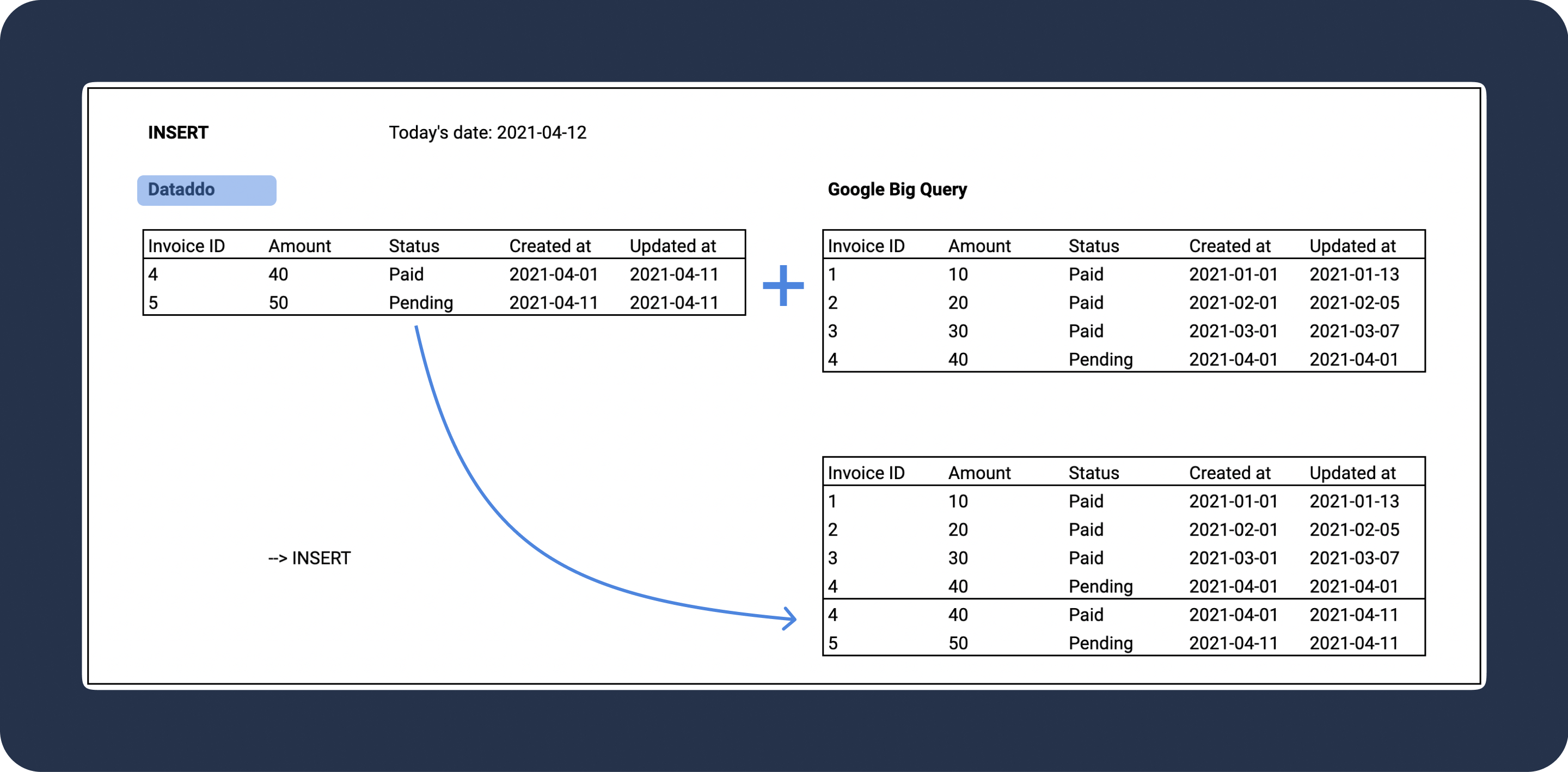
To avoid duplicates due to overlapping data, the upsert write mode can be helpful. It ensures existing records aren't duplicated, even when data is extracted repeatedly.
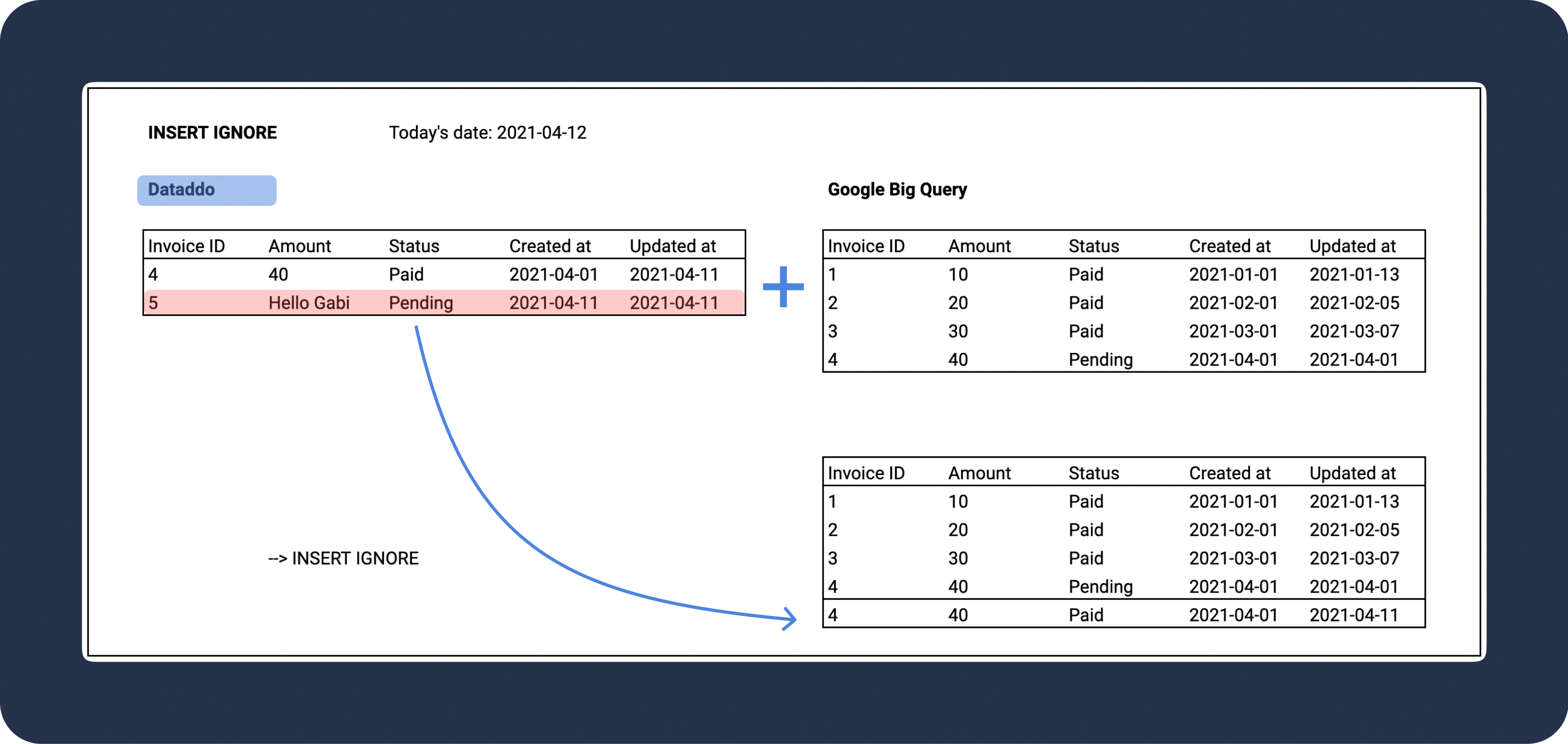
Insert Ignore
Insert Ignore write mode adds new data and bypasses error messages. If a record contains a mismatched data type, that record wikk be omitted. Insert ignore is not commonly used.
Example
Suppose the data type for the Amount column should be integer or float. If a field contains "Hello Gabi," which is a string, using insert ignore means this row will not be written into the database (omitted).
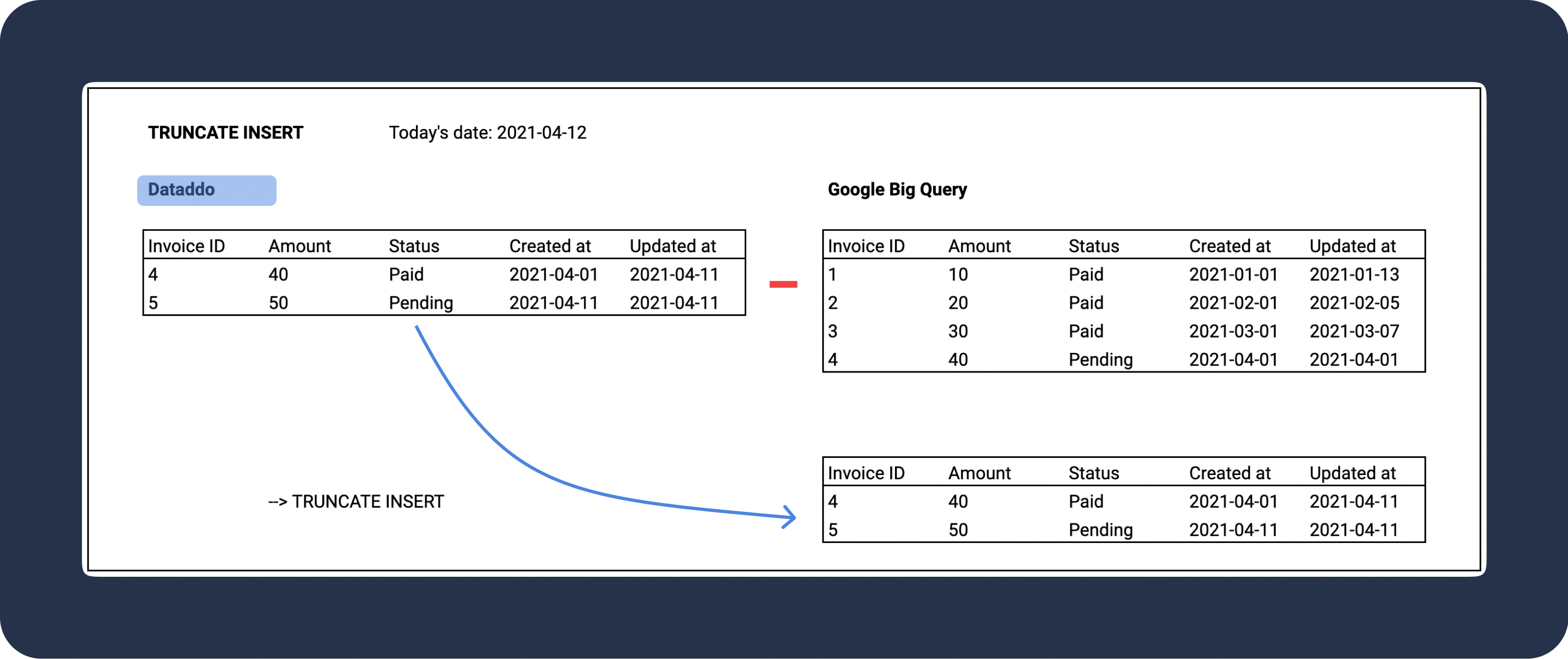
Truncate Insert
Truncate insert write mode first deletes all existing records in the destination table. After this, it inserts the newly extracted data.
Exercise caution when choosing this write mode. It will delete all existing records in the destination table before adding new data.
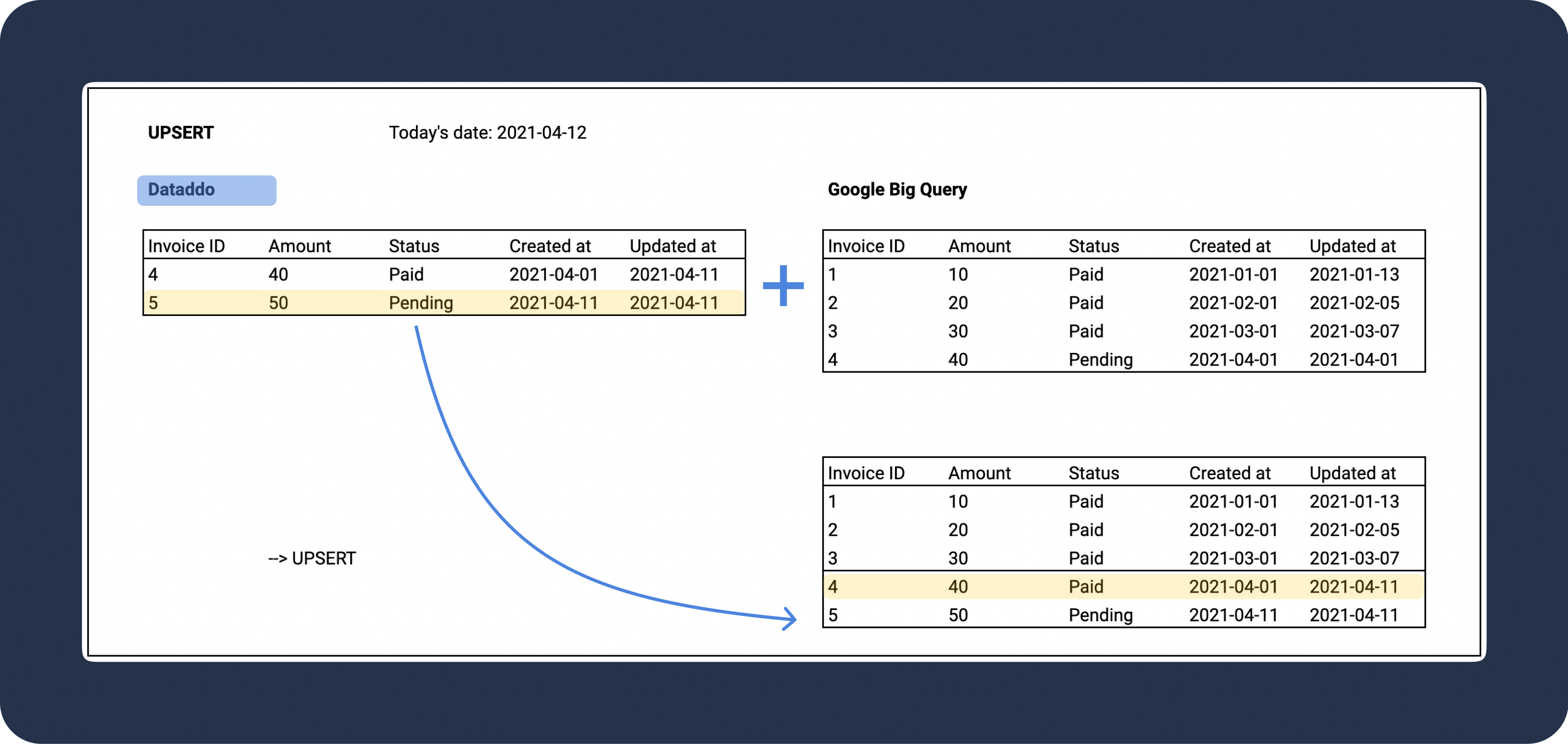
Upsert
Upsert write mode inserts new records and updates existing ones. To make use of this mode, you'll need to define a composite key. This key can be a single column or a combination of columns.
When using Upsert, Dataddo first checks the data in the destination. If a record with the same composite key is present, that record is updated. If not, a new record is added. This process effectively prevents data duplication.
Upsert Composite Key
A composite key (also called unique key) refers to one or more columns that uniquely identify a record in a table. When setting up the upsert write mode, you'll need to specify this key.
Example
Invoice ID is used as a composite/unique key.
Using Upsert with Specific Databases
When creating a data flow for MySQL, PostgreSQL, MSSQL, Amazon Redshift, or Vertica, Dataddo sets up the target table's structure, including indexing. This setup is automated for the first data load when the upsert write mode is chosen.
However, if you select upsert for an existing table, this automatic indexing won't occur. This can affect the upsert's functionality. To utilize upsert properly, select it during the setup of a new table.
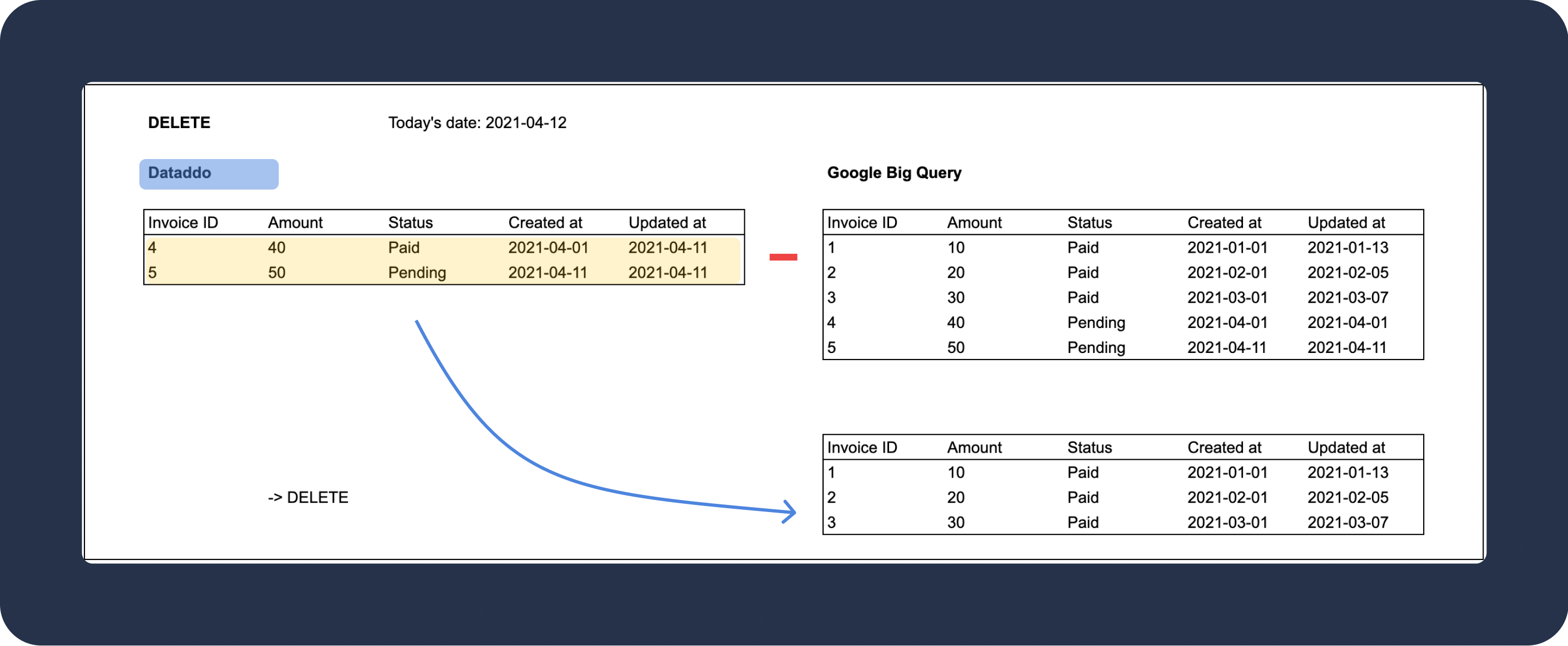
Delete
Delete write mode removes specific rows in the destination based on a designated delete composite key. If a row has a value that matches this key, it's deleted. While this mode is useful for ensuring data accuracy in specific scenarios, it's essential to use it with care to prevent unintentional data loss.
For a practical example of its use, see our article on database replication.
Delete Composite Key
A composite key (also called unique key) comprises one or more columns that uniquely identify each record in a table. When you set up the delete write mode for data storage, you'll need to specify this key.
Troubleshooting
Handling Data Duplicates in Storage
Data duplicates often arise from an inappropriate write mode selection.
By default, Dataddo uses the insert write mode, which appends all newly extracted data to the table. However, if there's an overlap between data extracts, this approach can lead to duplicates. To prevent this, consider switching to one of the following write modes:
- Truncate Insert: This mode clears the entire table in your storage before inserting new data.
- Upsert: This mode adds new rows and updates existing ones.